
LLMs understand geography better than you think
If we can accept some error, there are some applications where large language models can do things traditional geocoders can't.
Some of my exploratory work lately has been focused on geographic personalization: Basically, how might we pull apart news stories into pieces, then repackage those pieces for readers from specific cities, towns and neighborhoods?
One approach to that challenge requires identifying place mentions (regions, cities, landmarks, etc.) and assigning them reasonable latitude and longitude coordinates — a problem that sounds simple but presents a surprising number of weird edge cases that traditional geocoding tools don’t handle very well.
Fortunately it seems LLMs are better at understanding geography than you might expect, which creates space for some creative workarounds. That ability degrades as the geography gets more specific, but it can sometimes be “good enough,” especially if you’re seeking coordinates for areas that aren’t easily identified by traditional geolocation services.
LLMs as geocoders?
Here’s a quick experiment that demonstrates this idea.
We start by taking 188 random addresses from the National Address Database, which is a federal dataset containing more than 90 million addresses for various homes, businesses and landmarks from across the country. Each record contains a verified latitude and longitude, along with a text address.
For each address in the dataset, I’ve also added the geographic center of the city in which it is based, according to Pelias. This will serve as sort of a baseline against which we can measure the LLM’s geolocation performance. Traditional geocoders often fall back to city centers if they can’t locate a precise address, so any performance over that baseline could represent a potentially useful improvement.
GPT-5 APIs can still be pretty slow, so I use GPT-4o to attempt to estimate a latitude and longitude for each address. Basically, I ask it to act like a zero-shot geocoder.
You can see the entire experiment in this notebook.
The results
The median error of points estimated by GPT-4o was about 1.5 miles away from the ground-truth points (using geodesic distance). By contrast, the median error using city centers was about 2.5 miles.
You might take this as evidence that GPT-4o isn’t great at geocoding addresses, and you would be right. Just to say it out loud, large language models are not geocoders, nor should we expect them to be.
But consider, too, that 1.5 miles isn't that far off. Given that language models presumably acquire their geographic understanding through textual tokens, not formal geographic systems, that level of performance is actually kind of impressive (at least to me).
For a certain subset of tasks where precision isn’t critical, knowing that large language models contain some reasonable knowledge of geography can actually help us do some things traditional geocoders can't.
Geocoding regions
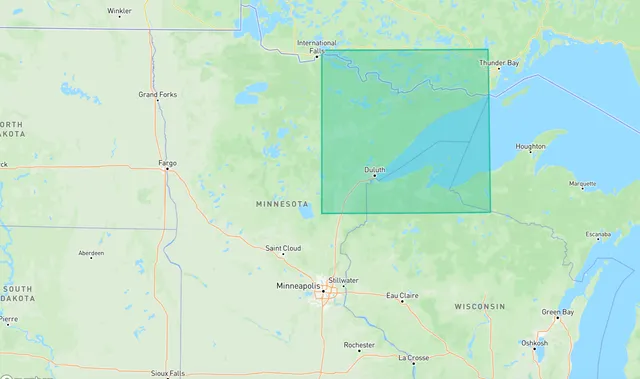
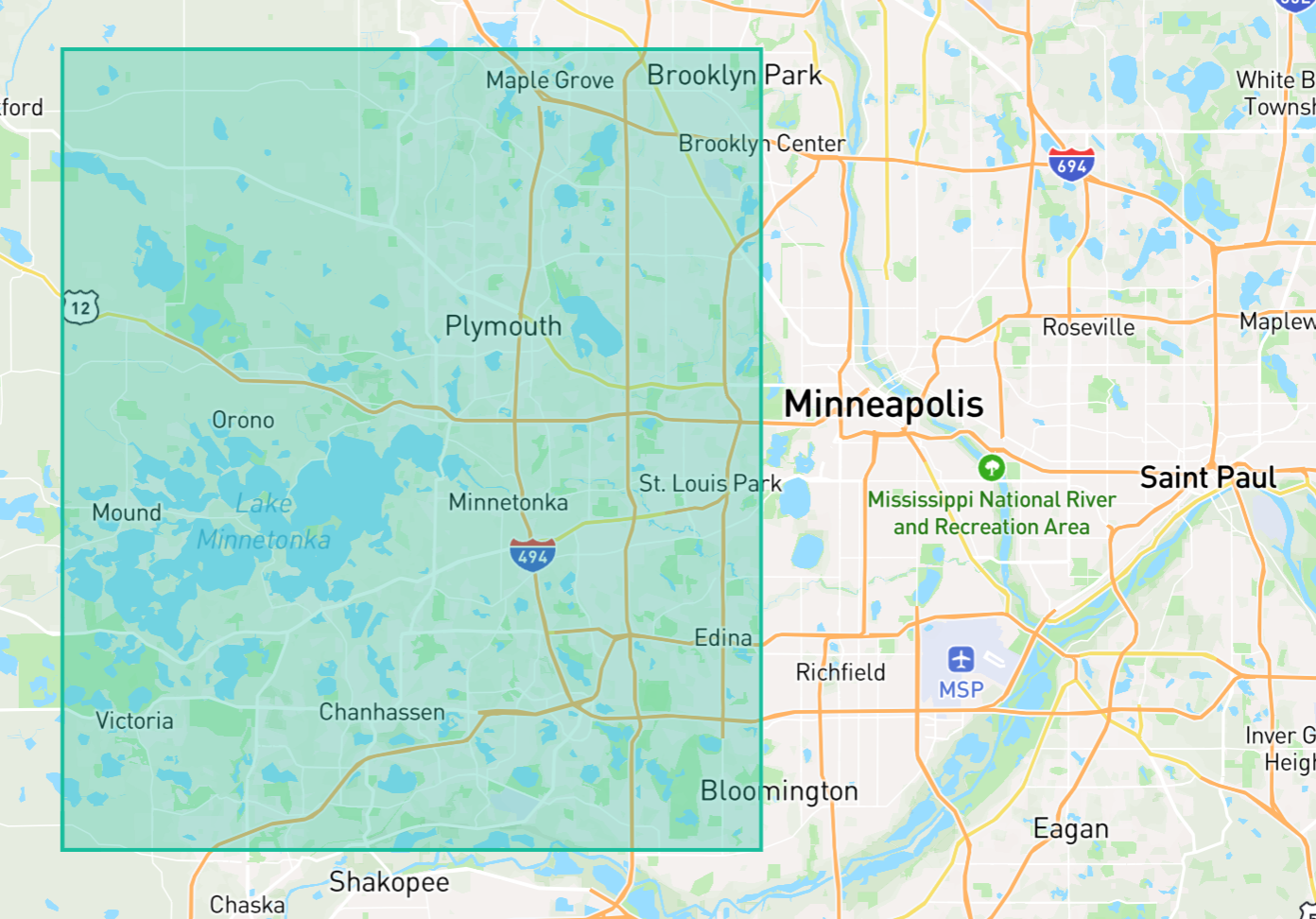
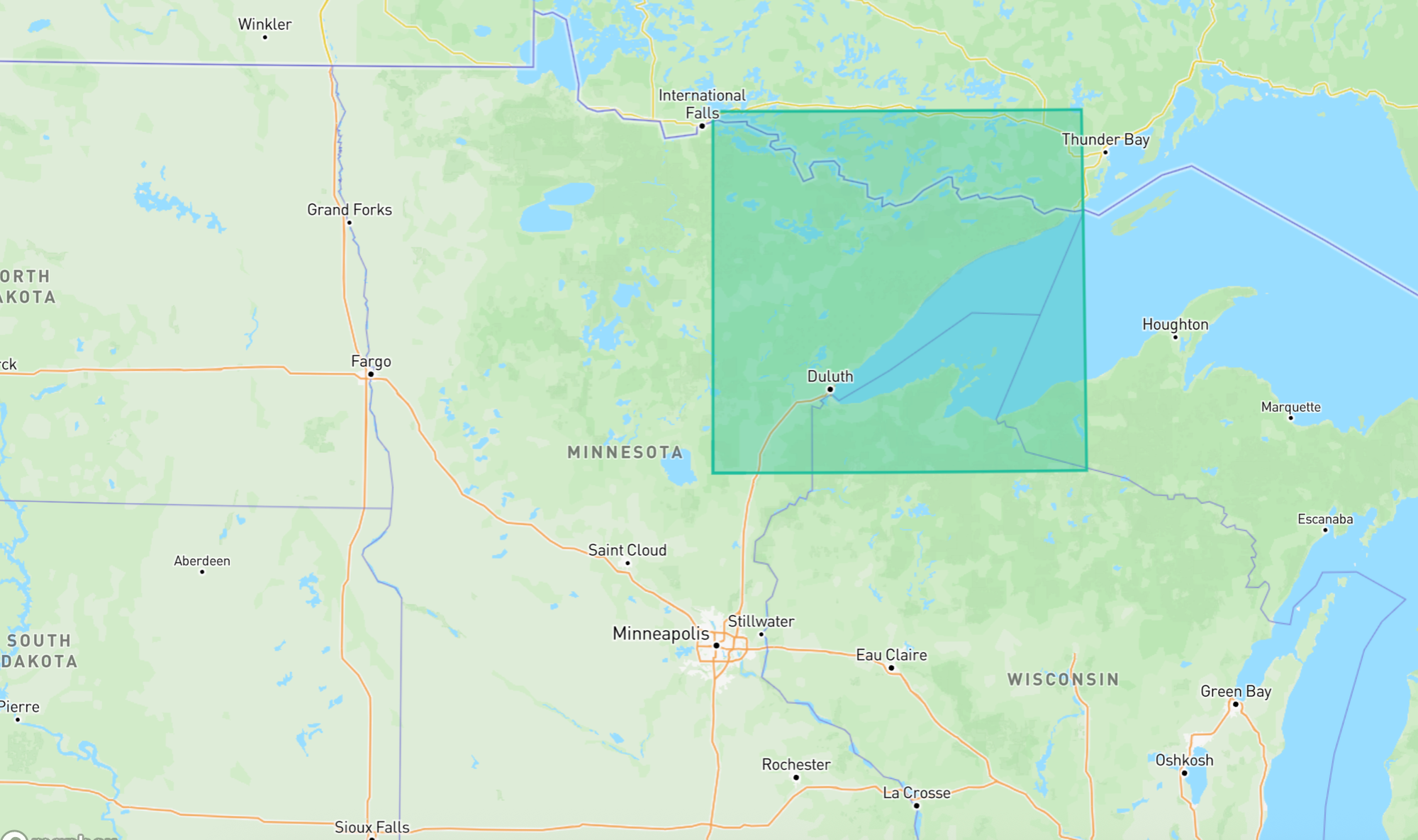
For example, identifying areas without formal boundaries. Say "the western suburbs of Minneapolis" or "the Minnesota Arrowhead."
If you asked five different people to draw bounding boxes around those areas, you'd get five different answers. And traditional geocoding services offer responses that are all over the map, from choosing a single representative place within a region to not returning anything at all.
In situations like this, we might be satisfied with a reasonable guess — and GPT-4o offers as good of a guess as any. Here's what it comes back with for the two regions described above.
Takeaways
It should come as no surprise that we can't expect large language models to excel at precise geolocation. That's not what they're built for.
That said, very few estimates made by an LLM in this experiment were wildly off base. If we can accept some error, there are some applications where the imperfect guesses of large language models might still be better than nothing.
Outside Angles
Here are a few interesting things I've been reading this week:
- Boring is good: I think some of the best uses of LLMs are also the most boring ones, so this resonated with me.
- You can now train a 70b language model at home: A good reminder that the cost and complexity of training models continues to come down.
- Semantic Line Breaks: An old idea that has new relevance with RAG chunking. Also, this is kind of what newswriting structure is. Can we exploit that somehow in building AI applications?
- Assessing the quality of information extraction: This paper proposes an interesting method to evaluate the accuracy of LLM-powered information extraction using a concept the authors call "needles." It's a tricky problem to evaluate at scale, so I might have to give this a shot ...